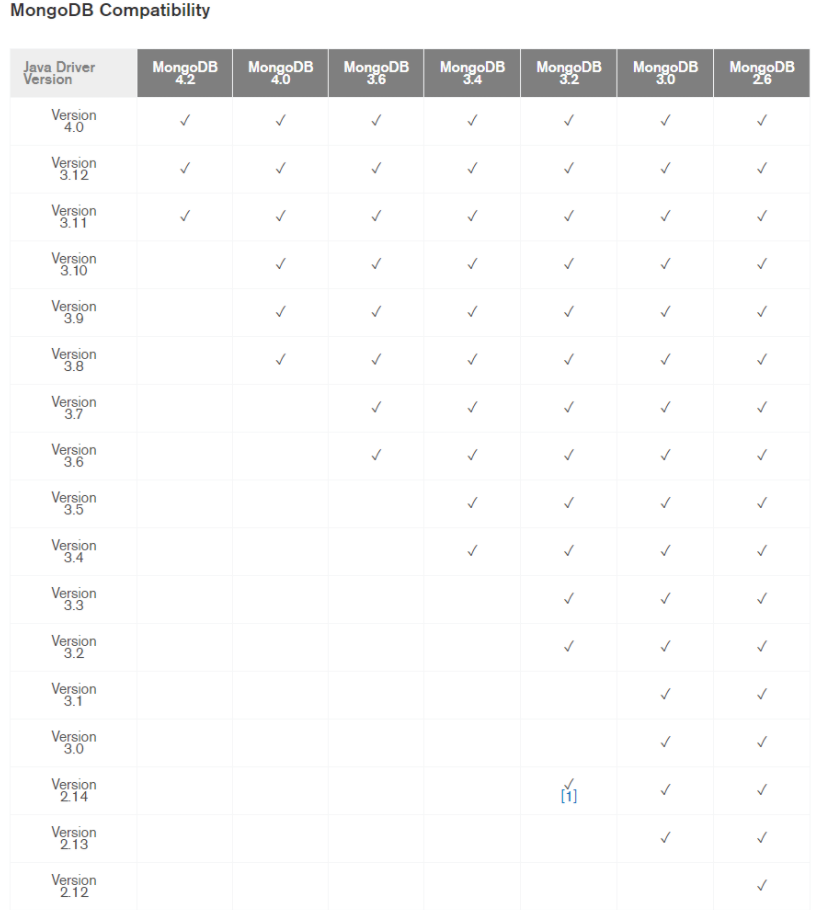
java 8버전 이상 필요
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.ZonedDateTime;
import java.time.format.DateTimeFormatter;
import java.util.Locale;
/**
* 타임존 변환 샘플 소스
*
* @author
*/
public class TimeZoneConvert {
public static void main(String[] args) {
pstData();
}
/**
* PST로 변환 샘플
* - 참고: mysql 기준 쿼리 샘플 SELECT CONVERT_TZ( NOW(), 'UTC', 'Asia/Seoul') AS kst, CONVERT_TZ(NOW(), 'UTC', 'America/Los_Angeles') AS PST
*/
public static void pstData() {
DateTimeFormatter strFMT = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"); //문자 출력용 포맷
//PST(Pacific Standard Time). 태평양표준시로 UTC-8. PST는 흔히 LA타임으로 불리며, ZoneID는 'America/Los_Angeles' 임
//PST와 KST는 17시간 차이가 남(PST가 17시간 늦음). KST->PST는 17시간 빼면됨
//String targetStrPST = "Mar 1, 2021 11:42:23 PM PST"; //KST 기준으로 2021-03-02 16:42:23
String targetStrPST = "Mar 4, 2021 05:32:33 PM PST"; //KST 기준으로 2021-03-02 16:42:23
DateTimeFormatter targetFMT = DateTimeFormatter.ofPattern("MMM d, yyyy hh:mm:ss a z", Locale.ENGLISH); //대상 문자 PST의 포맷
LocalDateTime targetPstDT = LocalDateTime.parse(targetStrPST, targetFMT);
ZonedDateTime pstZDT = targetPstDT.atZone(ZoneId.of("America/Los_Angeles")); //PST는 ZoneId가 'America/Los_Angeles' 임
System.out.println("PST ymdt=> " + pstZDT.toLocalDateTime().format(strFMT));
ZoneId kstZoneId = ZoneId.of("Asia/Seoul");
LocalDateTime kstDT = pstZDT.withZoneSameInstant(kstZoneId).toLocalDateTime(); //KST로 변환
String kstStr = kstDT.format(strFMT);
System.out.println("KST ymdt => " + kstStr);
System.out.println("KST ymdt toEpochSecond(유닉스 타임스탬프) => " + kstDT.toEpochSecond(kstZoneId.getRules().getOffset(kstDT)));
}
/**
* PDT로 변환 샘플
*/
public static void pdtData() {
final ZoneId pdtZoneId = ZoneId.of("GMT-07:00"); //PDT는 GMT-07:00
final DateTimeFormatter strFMT = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"); //문자 출력용 포맷
//참고링크: https://savvytime.com/converter/pdt-to-kst-utc/aug-1-2021/3am
String targetStrPDT = "Aug 1, 2021 12:03:00 AM PDT"; //KST 기준으로 2021-08-01 16:03:00이고, UTC기준으로는 2021-08-01 07:03:00
DateTimeFormatter targetFMT = DateTimeFormatter.ofPattern("MMM d, yyyy hh:mm:ss a z", Locale.ENGLISH); //대상 문자 포맷
LocalDateTime targetPdtDT = LocalDateTime.parse(targetStrPDT, targetFMT); //PDT의 LocalDateTime 객체가 생성됨
// @formatter:off
System.out.println(
String.format(
"PDT 테스트 문자열: %s\n"
+ "PDT LocalDateTime: %s\n"
+ "PDT EpochSecond: %s\n"
+ "PDT -> UTC LocalDateTime: %s\n"
+ "PDT -> KST LocalDateTime: %s",
targetStrPDT,
targetPdtDT.format(strFMT),
targetPdtDT.atZone(pdtZoneId).toEpochSecond(),
targetPdtDT.atZone(pdtZoneId).withZoneSameInstant(ZoneId.of("UTC")).toLocalDateTime().format(strFMT),
targetPdtDT.atZone(pdtZoneId).withZoneSameInstant(ZoneId.of("Asia/Seoul")).toLocalDateTime().format(strFMT)
)
);
}'JAVA > Java 일반' 카테고리의 다른 글
| 구글 재무보고서 중에서 '수익'보고서를 다운로드하는 샘플 프로그램(download google earnings report) (1) | 2021.11.26 |
|---|---|
| 구글 수익 레포트 CSV파일 파싱 프로그램(Parsing Google earnings report csv file) (0) | 2021.11.18 |
| CSV파일을 읽어서 파싱하여 DB(Mysql)에 저장하는 프로그램 샘플 (0) | 2021.11.12 |
| CSV파일 파싱 샘플(with apache commons-csv) (0) | 2021.11.12 |
| java 2글자국가코드_및_국가명_리스트조회 프로그램 (0) | 2021.08.05 |